SEO optimisation on LLMs – How to become visible on new search engines
Learn more about our expertise Agence SEO02/12/2024 31 min. reading Leslie
As ChatGPT, Perplexity, Gemini, and other large language models (LLMs) gain popularity, brands have one fear: disappearing from search engines. By providing answers directly to users, these generative AIs are disrupting the SEO strategies of many companies.
But to respond to users with complete transparency, LLMs must provide their sources. And that’s where generative AI optimisation comes in. With this new generation of natural referencing, you can become visible on any AI-powered search engine. Let’s take a closer look.
Exploring generative AI and large language models
Why understanding TAL and LLM is crucial:
Becoming familiar with natural language processing (NLP) and large language models (LLMs) is an essential step in anticipating developments in search engine optimisation, digital branding and content strategies. A thorough understanding of these technologies allows their full potential to be exploited.
The ideas presented here are based on a decade of work in semantic research, in-depth studies of scientific literature, and analysis of patents related to generative AI.
How large language models work
The basics of LLMs
Before adopting tools such as GEO (Generative Engine Optimisation), it is essential to understand the technological foundations of LLMs. Just as it is essential to master search engines to avoid ineffective practices, investing a few hours in learning these concepts can save time and resources by ruling out irrelevant strategies.
LLMs: a revolutionary advance
Language models such as GPT, Claude, and LLaMA represent a major transformation in the way generative AI and search engines process queries.
They do not simply search for textual matches, but generate nuanced and contextually rich responses, thanks to their advanced linguistic comprehension and reasoning capabilities. For example, research such as Microsoft’s “Large Search Model: Redefining Search Stack in the Era of LLMs” highlights their role in reshaping search technologies.
Advanced LLM features in search
LLMs adopt a unified approach to treating all research-related tasks as text generation problems. This enables them to:
Generate comprehensive responses: They produce summaries in natural language, going beyond simple information extraction.
Customise responses: Thanks to specific prompts, templates adapt their results to users’ needs.
Improving queries: In cases of insufficient data, LLMs generate additional queries to collect more relevant information.
Key stages of treatment with LLM
Encoding: structuring data
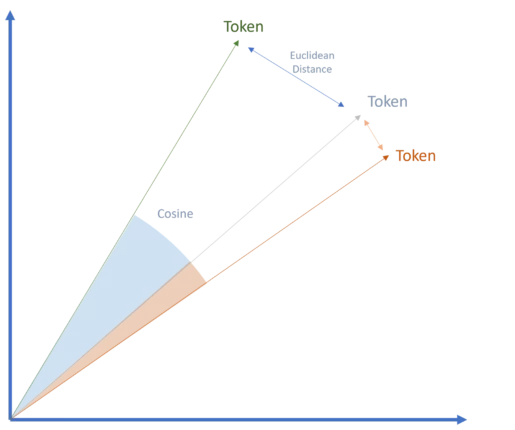
Raw data is transformed into tokens, the fundamental units of models. These tokens represent various types of information (words, entities, images, etc.) depending on the application.
Transforming tokens into vectors
Tokens are converted into vectors, an essential step in transformer-based models such as Google’s technology. These vectors, which are numerical representations of tokens, capture their specific attributes and enable semantic relationships to be measured using methods such as cosine similarity or Euclidean distance.
This vector- and transformer-based approach revolutionised generative AI and remains a key factor in the widespread adoption of LLMs today.
The decoding process
Decoding is the stage where the model interprets the probabilities associated with each possible next token (word or symbol). The aim is to produce a fluid and natural sequence.
Decoding techniques
To achieve this objective, several methods are used:
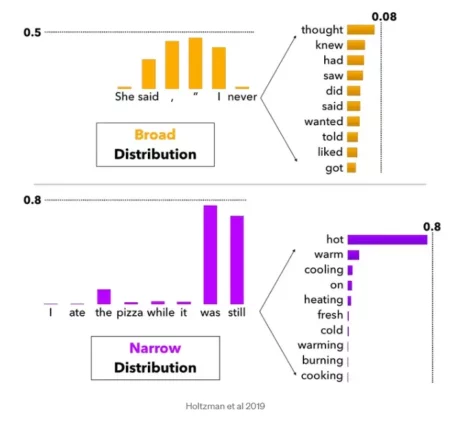
Top K sampling: Considers the K most probable words as options for the next step.
Top P sampling: Takes into account words whose cumulative probabilities reach a certain threshold (P), allowing for greater variation.
These methods influence the model’s level of creativity. For example, a “strict” model favours the most probable options, producing consistent and predictable responses, while a “more flexible” model explores alternatives, generating varied responses.
Diversity of outputs and creativity
The choice of decoding method explains why the same prompt can produce different results. With greater creative freedom, models consider a wider range of potential words, which encourages more original and nuanced responses.
Beyond text: the multimedia capabilities of generative AI
Although encoding and decoding processes are mainly associated with text processing, they also apply to other formats such as audio and visuals. These contents are first converted into text tokens before being processed by the models.
For GEO applications, this multimedia capability is less relevant. However, the expanded context window of LLMs provides a better understanding of the relationships between primary and secondary entities in sentences, thereby enriching the results produced.
Challenges and solutions of generative AI
Large language models (LLMs) face three main challenges:
Updating information: Preventing answers from becoming obsolete.
Reducing hallucinations: Ensuring the accuracy of responses.
Thematic accuracy: Provide detailed information on specific topics, rather than generic answers.
To remedy this, recovery-augmented generation (RAG) is emerging as an effective solution.
Augmented Generation through Recovery (AGR): How it Works and Its Benefits
RAG enriches LLMs by providing them with subject-specific data, integrated in the form of documents or vectors representing complex semantic relationships (as in knowledge graphs).
This approach enables:
A better understanding of the relationships between entities.
Greater precision in thematic responses.
Applications and challenges for GEO
RAG provides opportunities for tools such as GEO by facilitating access to relevant sources and enabling customisation of the data used.
However, the challenge remains in determining how platforms select and evaluate the quality of sources, a key factor in ensuring the relevance and reliability of responses.
The importance of recovery models in RAG architecture
Retrieval models play a fundamental role in retrieval-augmented generation (RAG) systems, acting as “specialised librarians” capable of identifying relevant information in huge data sets.
Operation and benefits
These models use advanced algorithms to evaluate and select the most useful data, incorporating external knowledge into text generation. This enables:
Enriched and contextualised content production.
An extension of the capabilities of classical language models.
Recovery systems rely on several technologies, including:
Vector incorporations and vector search.
Indexing documents using techniques such as BM25 or TF-IDF.
Variations and limitations of recovery approaches
Not all AI systems incorporate sophisticated retrieval mechanisms, which poses challenges for optimising RAG architectures.
Meta: Develops its own search engine for its LLaMA models, aiming for better control over the data retrieved.
Perplexity: Uses proprietary indexing and ranking systems, although it is sometimes accused of relying on results from engines such as Google.
Claude (Anthropic): Its use of RAG remains somewhat opaque, potentially combining user data and its own index.
Gemini, Copilot, and ChatGPT: Utilise their partners’ search engines (Microsoft Bing for ChatGPT) or develop proprietary solutions such as SearchGPT.
The case of ChatGPT and SearchGPT
OpenAI recently introduced SearchGPT, combining several technologies to enrich its responses:
A model based on a refined version of GPT-4, trained with synthetic data distillation techniques.
Partnerships with third-party search providers (including Microsoft Bing) and direct content from partners.
Although ChatGPT shows similarities with Bing’s rankings for certain queries, its model uses diverse sources, ensuring a certain degree of independence in its responses.
RAG pipeline assessment: key criteria
The evaluation of a recovery-augmented generation (RAG) system relies on several key metrics to measure its performance and reliability.
Key assessment criteria
Accuracy: Checks the factual consistency of responses in relation to the context provided.
Relevance of the response: Measures how well the generated response matches the prompt.
Context accuracy: Evaluates the correct classification of relevant contextual elements, with scores ranging from 0 to 1.
Anchoring: Verifies whether responses are directly supported by source information, ensuring their verifiability.
Source references: Ensures the presence of citations and links to facilitate verification.
Distribution and coverage: Ensures balanced representation among the various sources and sections consulted.
Accuracy of facts: Checks for the presence of accurate factual information in the generated content.
Custom criteria (aspect-based review): Enables evaluation based on specific aspects, such as accuracy or safety.
Specific performance indicators
Average Precision (MAP): Average of the precisions calculated for each query, taking into account the ranking of documents in the results. A high MAP reflects better relevance of search results.
Mean reciprocal rank (MRR): Measures how quickly the first relevant document appears in the results. A high MRR indicates that the most relevant results are ranked highly.
Autonomous quality: A score from 1 to 5 that assesses whether the generated content is understandable without external context.
Difference between prompts and queries
Queries: Often keywords or short phrases, they target specific results in a classic search.
Prompts: Formulated in natural language, they provide more detailed context and allow for more nuanced responses.
In RAG systems, the prompt is transformed into a background query to efficiently query databases while preserving the original context, improving the accuracy and relevance of responses.
Optimisation of AI previews and AI assistants
AI snippets (Google SERP): Generated from search queries, they provide direct extracts in response.
AI assistants: Based on complex prompts, they offer richer, more contextualised responses.
To bridge the gap between the two, RAG adapts complex prompts into queries while preserving critical context, ensuring optimal retrieval of relevant sources.
GEO objectives and strategies
The objectives of GEO (Global Entity Optimisation) vary according to the ambitions of the stakeholders:
Being cited in source links: This strategy aims to include content directly referenced in sources cited by generative AI systems.
Obtain direct mentions: This involves increasing the likelihood that your brand, product, or name will be included in AI-generated responses.
Although these objectives are complementary, they require distinct approaches. In both cases, it is essential to establish a strong presence among the sources favoured or frequently consulted by language models.
Prioritisation of linguistic models
Each AI assistant uses specific criteria to select and recommend entities. This involves:
Understanding LLM mechanisms: Studying the differences between large language models such as Gemini, Copilot, ChatGPT, and Perplexity.
Monitor emerging markets: Identify applications that dominate specific sectors or regions.
For professionals accustomed to focusing on Google, this requires a strategic shift, incorporating a variety of platforms and constantly monitoring market developments.
Mentions and citations in generated responses
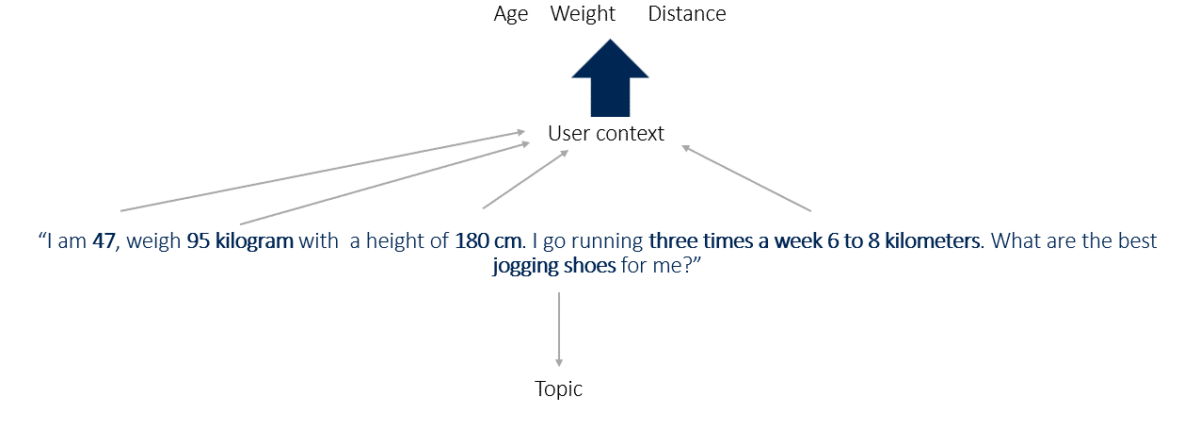
AI systems use contextual attributes to structure their responses. For example:
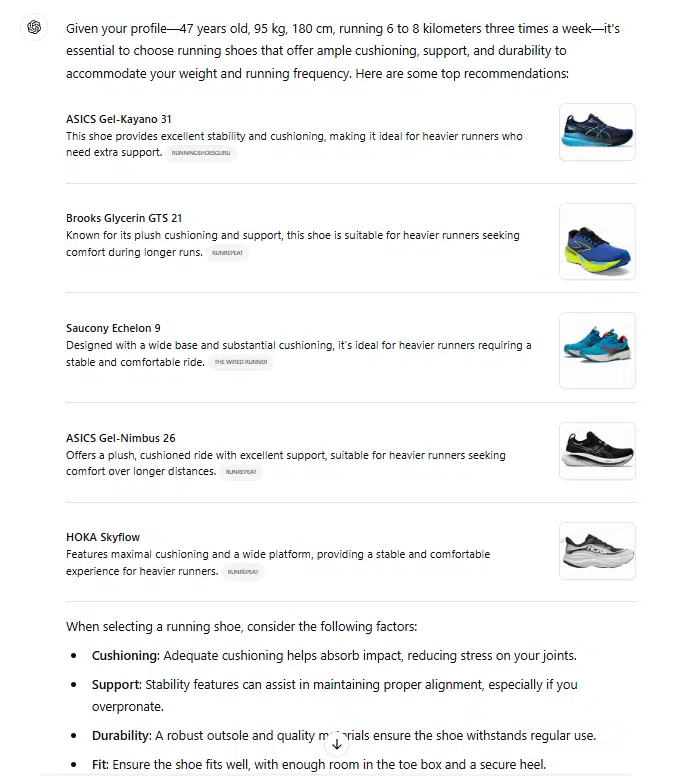
Example prompt: “I am 47 years old, weigh 95 kg, am 180 cm tall and run 3 times a week for 6 to 8 kilometres. What are the best jogging shoes for me?”
Contextual attributes: age, weight, height, running frequency and distance.
Main entity: jogging shoes.
Products or services frequently associated with these contexts are more likely to be mentioned by AI systems.
Insights into source selection
Platforms such as ChatGPT and Perplexity demonstrate how AI systems identify and cite content based on queries:
Headlines such as “The best shoes for heavy runners in 2024” or “The 7 best long-distance running shoes” show that AI deduces specific information from user attributes.
Working upstream to align your content with AI assistant criteria is therefore crucial to maximise visibility and mentions in the responses generated.
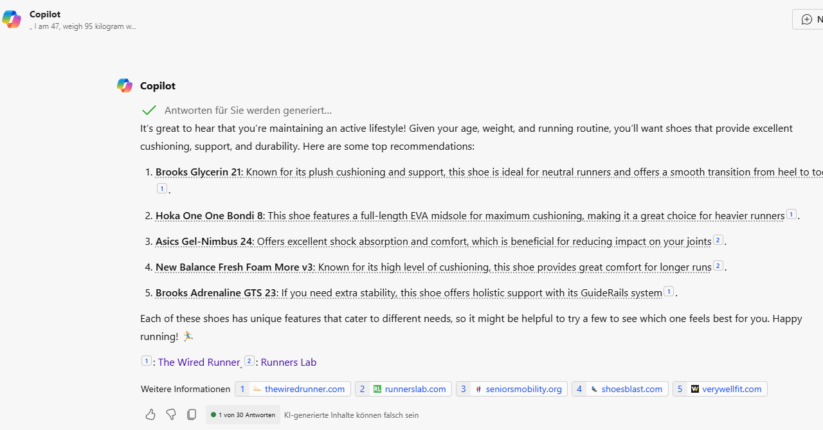
Co-pilot
Copilot analyses attributes such as age and weight to contextualise responses.
Based on the data provided, he can deduce a context of overweight by referring to the sources cited.
The sources cited come exclusively from informative content, such as tests, reviews and rankings, rather than e-commerce pages or detailed product descriptions.
ChatGPT
ChatGPT takes into account attributes such as distance travelled and weight. Based on the referenced sources, it deduces a context of being overweight and long-distance running.
The sources cited come exclusively from informative content, such as tests, reviews and rankings, rather than from e-commerce pages, such as product descriptions or categories.
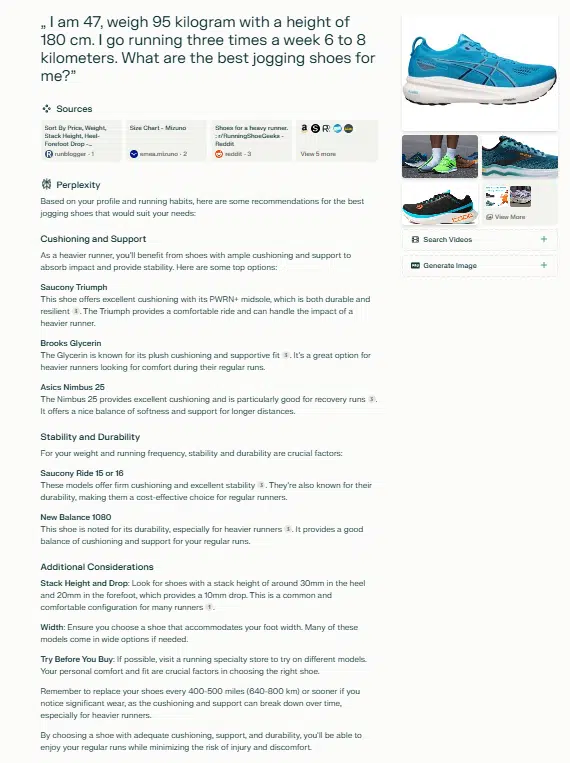
Perplexity
Perplexity takes into account the weight attribute and deduces a context of overweight from the referenced sources.
Sources include informative content such as tests, reviews, rankings, as well as traditional e-commerce pages.
Gemini
Gemini does not directly provide sources in its results. However, further analysis shows that it also takes age and weight contexts into account.
Gemini release – invitation to choose the best running shoes Gemini sources – invitation to choose the best running shoes
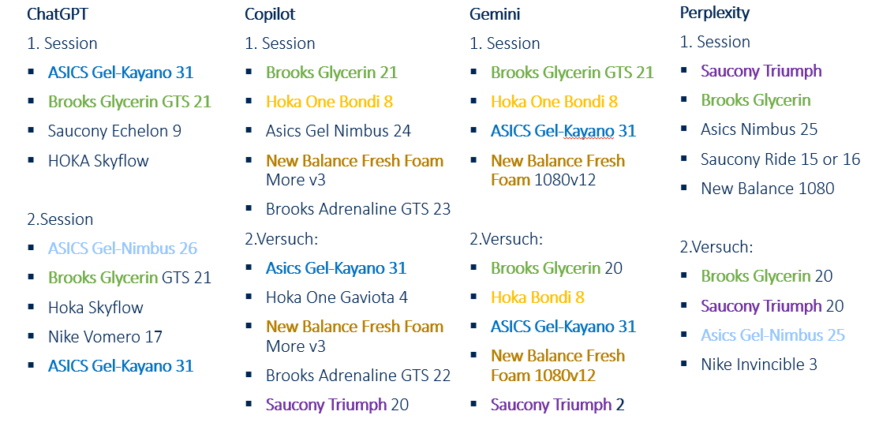
Each major LLM recommends different products, but one shoe is consistently suggested by all four AI systems tested.
Each major LLM offers different products, but one shoe is consistently recommended by all four AI systems tested.
All systems show some creativity, suggesting different products during various sessions. Copilot, Perplexity, and ChatGPT favour non-commercial sources, such as review sites or test pages, in line with the prompt’s objective.
Although Claude offers shoe models, it relies solely on its initial training data, without access to real-time data or a retrieval system.
Each LLM has its own process for selecting sources and content, making the GEO challenge more complex. Recommendations are influenced by co-occurrence frequency and context, which increases the likelihood of certain tokens during decoding.
Selection of sources and information for augmented generation through recovery
GEO emphasises the strategic positioning of products, brands, and content in the datasets used to train LLMs. Understanding the training process of these models in detail is crucial for identifying integration opportunities.
The information presented below is drawn from studies, patents, scientific publications, EEAT research, and personal analysis. The main questions raised are:
What is the influence of retrieval systems in the RAG (Retrieval-Augmented Generation) process?
What is the role of initial training data?
What other factors may influence the results?
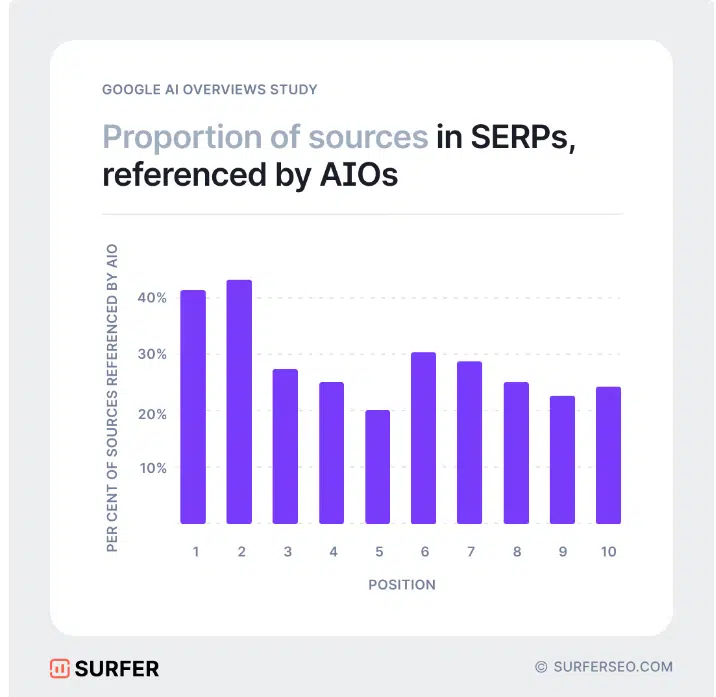
Recent work, particularly on the selection of sources for tools such as AI Overviews, Perplexity, and Copilot, highlights significant overlaps in the sources used.
For example, analyses conducted by Rich Sanger, Authoritas, and Surfer show that the snippets generated by Google AI display approximately 50% overlap in their selection of sources.
Analysis of fluctuation margins and the impact of recovery systems
The margin of fluctuation in study overlaps remains significant. At the beginning of 2024, the overlap rate stood at around 15%, although it reached up to 99% in some analyses.
Recovery systems appear to influence nearly 50% of the results of AI-generated previews, indicating ongoing experiments aimed at optimising performance. These observations corroborate criticisms about the variable quality of the responses produced by these systems.
The selection of sources used in AI responses reveals strategic opportunities to position brands or products in a contextually relevant manner. However, it is crucial to distinguish between:
The data sources used for the initial training of models, which shape their basic understanding.
Sources added for specific topics, integrated during the retrieval-augmented generation (RAG) process.
Examining the model training process sheds light on these distinctions. For example, Gemini, Google’s large multimodal model, processes diverse data such as text, images, audio, video, and code. It uses web documents, books, code, and multimedia content for training, enabling it to handle complex tasks efficiently.
Finally, analyses of AI insights and the most frequently referenced sources offer valuable insight into the indices and Knowledge Graph used by Google during model pre-training. This paves the way for alignment strategies to include relevant content.
In the RAG process, domain-specific sources are integrated to enhance the contextual relevance of responses.
A key feature of Gemini is its use of a mixture of experts (MoE) architecture. Unlike traditional transformers, which rely on a single neural network, a MoE model is composed of smaller, specialised “expert” networks. This model selectively activates the most relevant expert paths based on the input data, optimising the efficiency and performance of the system. It is likely that the RAG process will be integrated into this architecture.
Developed by Google, Gemini undergoes several training stages, using publicly available data and advanced techniques to maximise the relevance and accuracy of the content generated:
Pre-training Like other large language models (LLMs), Gemini is first pre-trained on a variety of public data sources. Google applies various filters to ensure data quality and avoid undesirable content. This phase also involves flexible selection of probable words, allowing the model to generate more creative and contextually appropriate responses.
Supervised fine-tuning (SFT) After pre-training, the model is refined using high-quality examples, either created by experts or generated by other models and then reviewed by specialists. This process is similar to learning good textual structure by observing examples of well-written texts.
Reinforcement learning from human feedback (RLHF) The model is then refined through human evaluations. A reward system based on user preferences helps Gemini recognise and learn preferred response styles and content types.
Extensions and augmentation through retrieval Gemini can search external data sources, such as Google Search, Maps, YouTube, or other specific extensions, to enrich responses with up-to-date contextual information. For example, to answer questions about the weather or current events, Gemini can query Google Search directly to find reliable, recent information and then incorporate it into its response.
The model filters search results to include only the most relevant information based on the context of the query. For example, for a technical question, it will prioritise scientific or technical results over general information available on the web.
Gemini combines the retrieved data with its internal knowledge to generate an optimised response. This process includes creating a logically structured and readable response, followed by a final review to ensure that it meets Google’s quality standards and does not contain inappropriate content. This quality control is reinforced by a ranking system that prioritises the most relevant responses. The model then presents the highest-ranked version to the user.
User feedback and continuous optimisation
Google constantly takes into account feedback from users and experts to refine the model and correct any weaknesses. One possibility being considered is that AI applications could access existing search systems and integrate their results.
Some studies suggest that a high ranking in search engines increases the likelihood that a source will be cited in AI applications connected to them. However, as analyses have shown, current overlaps do not yet reveal a clear link between the highest rankings and the sources used.
Another criterion seems to influence the choice of sources: Google’s approach favours compliance with quality standards when selecting sources for pre-training and the RAG process. In addition, the use of classifiers is also cited as a determining factor in this process.
When naming classifiers, a link can be established with the concept of EEAT, where quality classifiers also play a key role.
The information provided by Google on post-training also mentions the use of EEAT to classify sources according to their quality.
The reference to assessors refers to the role of quality assessors in the EEAT assessment.
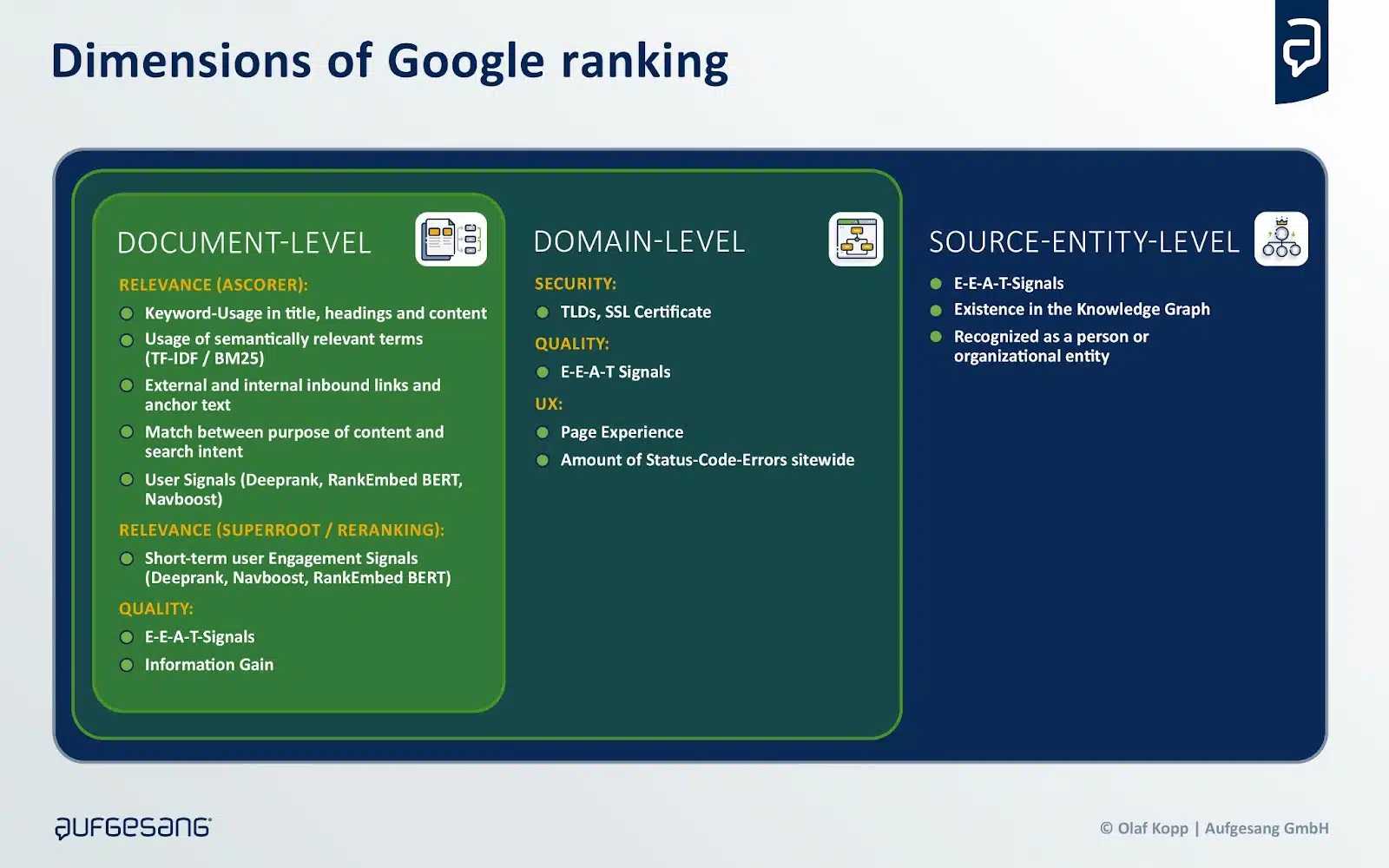
Rankings in most search engines depend on the relevance and quality of information, both in terms of the document, the domain, and the author or source entity.
Sources are often selected not only for their relevance, but also for their quality in terms of the subject area and the source entity.
This can be explained by the fact that more complex queries must be rewritten in the background to generate appropriate search queries for querying the rankings. Although relevance varies depending on the query, quality remains a constant criterion.
This distinction helps to understand the weak correlation between search engine rankings and sources referenced by generative AI, and why lower-ranked sources may sometimes be included.
To evaluate quality, search engines such as Google and Bing use classifiers, including Google’s EEAT framework. Google specifies that EEAT can vary depending on the domain, thus requiring strategies tailored to each subject, particularly in GEO strategies.
The sources used differ depending on the sector or subject, with platforms such as Wikipedia, Reddit and Amazon playing various roles, as indicated by a study by BrightEdge.
Therefore, industry- and subject-specific factors must be taken into account in positioning strategies.
Tactical and strategic approaches for LLMO/GEO
As mentioned earlier, there is still no tangible evidence regarding the direct influence on the results of generative AI. Platform operators themselves seem uncertain about how to qualify the sources chosen during the RAG process.
These factors highlight the importance of identifying areas where optimisation efforts should be focused, particularly by determining which sources are sufficiently reliable and relevant to be prioritised.
The next challenge is to understand how to position yourself as one of these authoritative sources.
The research paper entitled “GEO: Generative Engine Optimisation” introduced the concept of GEO, exploring how generative AI outcomes can be influenced and identifying the key factors responsible for this influence.
According to the study, the visibility and effectiveness of the GEO can be optimised by the following elements:
Authority in writing: It improves performance, especially on debate questions or queries in historical contexts. More persuasive writing is indeed more valuable in these situations where argumentation plays a central role.
Quotations (source references): These are particularly useful for factual questions, as they provide a source for verifying information, thereby reinforcing the credibility of the generated response.
Statistical addition: Highly effective in fields such as law, government, or public opinion, incorporating relevant statistics into web page content can improve visibility in specific contexts.
Direct quotations: These have a more significant impact in fields such as social sciences, history or personal narratives, as they add authenticity and depth to responses.
These factors vary depending on the domain, suggesting that integrating targeted, sector-specific personalisation is essential for increasing the visibility of web pages.
The following tactical measures for GEO and LLMO can be derived from this document:
Use citable sources: Incorporate reliable and verifiable sources into your content to reinforce credibility and authenticity, especially for factual information.
Add statistics: Include relevant statistics to support your arguments, particularly in areas such as law, government, or opinion issues.
Use quotations: Enrich content with quotations in fields such as social sciences, history, or explanations, as they add depth and authenticity.
Domain-specific optimisation: Take into account the specific characteristics of your sector when optimising, as the effectiveness of GEO techniques can vary depending on the domain.
Focus on content quality: Create high-quality, relevant, and informative content that meets the real needs of users.
Furthermore, certain tactical practices should be avoided:
Avoid keyword stuffing: Traditional keyword stuffing does not generally lead to significant improvements in AI-generated results and should be avoided.
Do not ignore the context: Avoid generating content that is unrelated to the subject or that does not add value for the user.
Do not overlook user intent: Ensure that your content truly meets users’ expectations and needs based on their search queries.
According to BrightEdge’s research, here are the strategic considerations to take into account:
Different impacts of backlinks and co-citations
AI and Perplexity insights favour distinct sets of domains depending on the sector. In the fields of health and education, these platforms favour reliable sources such as mayoclinic.org and coursera.com, making them key targets for effective SEO strategies. In contrast, in the e-commerce and finance sectors, Perplexity favours sites such as reddit.com, yahoo.com, and marketwatch.com. Tailoring your SEO efforts to these preferences using backlinks and co-citations can significantly improve performance.
Tailor-made strategies for AI-based research
AI-based search strategies must be tailored to each sector. For example, Perplexity’s preference for reddit.com shows the importance of community information in e-commerce, while AI Overviews favours sites such as consumerreports.org and quora.com for reviews and Q&As. Marketers and SEO specialists should align their content strategies with these trends by creating detailed product reviews or supporting Q&A forums for e-commerce brands.
Anticipating changes in the citation landscape
SEO specialists must closely monitor Perplexity’s preferred sites, particularly the growing influence of reddit.com for community content. Google’s partnership with Reddit could influence Perplexity’s algorithms, giving it greater priority. SEO specialists must remain proactive and adjust their strategies to adapt to changes in citation preferences, ensuring the relevance and effectiveness of their actions.
B2B technology
Establish a presence on authoritative websites: Publish on reputable domains such as techtarget.com, ibm.com, microsoft.com, and cloudflare.com, which are perceived as reliable sources.
Leverage content syndication: Take advantage of established platforms to quickly increase your citation as a reliable source.
Build your domain authority: In the long term, produce quality content to establish lasting authority, as competition for syndication spots will increase.
Partnerships with key platforms: Actively collaborate with industry leaders and contribute to their content.
Demonstrate your expertise: Display certifications, qualifications, and expert testimonials to signal your reliability.
E-commerce
Presence on Amazon: Focus on Amazon, which is a preferred source for Perplexity.
Promote product reviews: Highlight product reviews and user-generated content on Amazon and other relevant platforms.
Distributors and comparison sites: Distribute product information on established reseller platforms and comparison sites.
Syndication and partnerships: Syndicate content on reliable domains and establish partnerships with trusted sites.
Regularly update product information: Ensure that product descriptions are detailed and up to date on all sales platforms.
Get involved in community forums: Be active on platforms such as Reddit and other specialist portals.
Balanced marketing strategy: Combine a strong presence on external platforms with the development of your own domain authority.
Continuing education
Collaboration with authoritative websites: Work with websites such as coursera.org, usnews.com, and bestcolleges.com to create reliable sources.
High-quality, up-to-date content: Create well-structured, up-to-date content based on specialist knowledge.
Presence on community platforms: Be active on Reddit and other relevant forums, as community content is becoming essential.
Optimising your content: Use a clear structure and concise headings to optimise your content for AI systems.
Highlight certifications and accreditations: They reinforce the credibility and reliability of your content.
Finance
Presence on reliable financial portals: Use platforms such as yahoo.com and marketwatch.com, which are preferred sources for AI.
Keeping information up to date: Ensure that financial information is accurate and current on major platforms.
High-quality, factual content: Create verifiable content backed by recognised sources.
Active presence on Reddit: Get involved in relevant financial communities, as Reddit is becoming increasingly popular with AI.
Partnerships with financial media: Collaborate with established financial media outlets to increase your visibility and credibility.
Demonstrate expertise: Showcase specialist knowledge, certifications, and expert testimonials.
Health
Link to reliable sources: Include references to websites such as mayoclinic.org, nih.gov, and medlineplus.gov.
Integration of medical trends: Regularly update content with the latest medical research.
Well-researched content: Provide detailed medical information backed by official institutions.
Credibility and expertise: Highlight certifications and qualifications to reinforce reliability.
Regular content updates: Adapt your content in line with new medical discoveries.
Balanced strategy: Use a combination of content on established health platforms and strengthening your own domain authority.
Insurance
Use reliable sources: Publish on reputable sites such as forbes.com and .gov sites to boost your credibility.
Accuracy of information: Ensure that all information about products and services is accurate and up to date.
Content syndication: Share your content on platforms such as Forbes to be cited as a reliable source more quickly.
Local relevance: Tailor your content to local markets and regulations in the insurance sector.
Restaurants
Presence on review platforms: Maintain a strong presence on Yelp, TripAdvisor, OpenTable, and GrubHub.
Positive reviews and ratings: Encourage customers to leave positive reviews and interact with them.
Complete information: Ensure that information about menus, opening hours, and photographs is complete and up to date.
Engagement with culinary communities: Actively participate in sites such as Eater.com and other food platforms.
Local SEO optimisation: Perform local SEO, as AI often favours local relevance.
Wikipedia entries: Maintain comprehensive and well-maintained Wikipedia entries.
Seamless online booking process: Offer a simple online booking service via relevant platforms.
Tourism / Travel
Optimisation of presence on travel platforms: Create attractive, optimised content for TripAdvisor, Expedia, Kayak, Hotels.com and Booking.com.
Comprehensive and authentic content: Provide detailed travel guides, tips, and reviews.
Optimising the booking process: Ensure that the booking process is simple and user-friendly.
Local SEO: Integrate optimisation for local searches, as AI favours localisation.
Encourage reviews on platforms: Be active on travel platforms and encourage users to leave reviews.
Collaborate with trusted partners: Develop partnerships with reputable travel websites to increase your visibility and credibility.
The future of GEO: implications for brands
The future of GEO, particularly in the context of AI-powered search such as ChatGPT, marks a significant shift for corporate marketing strategies. This is largely based on how consumer search behaviours are evolving and how companies are leveraging new technologies to position themselves in these environments.
Here is a summary of the key points of this development and what it means for brands:
1. The importance of GEO and generative AI
The rise of ChatGPT and Bing: If ChatGPT becomes a dominant generative AI application, ensuring that your brand is well positioned on Microsoft Bing (which powers ChatGPT) could become crucial to influencing AI applications. This development could enable Bing to regain market share from Google.
2. Key objectives for businesses:
Proprietary media as sources for LLM training: Companies must establish a presence in proprietary media by producing content that complies with EEAT (Expertise, Authoritativeness, Trustworthiness) principles. This ensures that the information provided is considered reliable and is used in the LLM training process.
Generate mentions in reputable media outlets: Being cited in authoritative platforms is essential for strengthening the perception of the brand by AI and ensuring strong co-occurrence of the brand with relevant attributes and entities in these media outlets.
Producing content optimised for RAG systems: Creating high-quality content that ranks well and is taken into account in RAG (Retrieval-Augmented Generation) systems is another key element of optimisation for AI.
3. Difference between niche markets and large markets
Niche markets: In these markets, it is easier to position oneself due to less competition. Fewer co-occurrences are needed to associate a brand with specific entities in LLM systems.
Large markets: In more competitive markets, where brands already have a strong presence, the task becomes more complex. Here, managing public perception on a large scale becomes essential, requiring considerable resources in public relations and marketing.
4. The role of traditional search engine optimisation
Although GEO or LLMO strategies require more substantial investments, traditional SEO can still play a key role in training LLM models, provided that high-quality, well-structured and relevant content is produced.
5. Digital management of authority
The concept of digital authority management is becoming crucial for businesses to prepare for the future. This involves structuring efforts in public relations, SEO, and content creation to ensure that the brand is perceived as a reliable and credible source by both users and AI.
6. Benefits for major brands
Major brands, with their public relations and marketing resources, will likely enjoy a substantial advantage in search engine rankings and generative AI results. Their ability to generate visibility and reinforce brand perception through mentions in reliable media outlets will enable them to position themselves more effectively.
Conclusion:
Businesses must focus not only on traditional SEO, but also on the co-occurrence of their brand with relevant entities and attributes in authoritative media. To succeed in a world dominated by generative AI, it will be crucial to optimise relationships on recognised platforms and invest in digital authority management to influence public perception on a large scale. 😊
This means that brands will need to adapt their strategies to ensure they are well positioned in both traditional search engines and AI-generated results, while anticipating rapid changes in the digital landscape.
SEO on LLMs: Optimizations to implement
SEO optimisation on LLMs involves making yourself visible on new search engines.
Whether it’s ChatGPT, Perplexity, Microsoft Copilot, or Gemini, every large language model uses a database to provide answers to internet users. With a few exceptions, this database is simply made up of the vast universe of the internet. In other words, LLMs draw their knowledge from the hundreds of thousands of websites on the web. Among them is undoubtedly yours.
Some language models use content without specifying the source to the user. However, for the sake of transparency, more and more of them are citing the source of the information they provide. Certain particularly relevant sites are thus able to make themselves visible on LLM tools. Users who want to find out more can then click on the site link and access its content.
But to do that, you still need to master SEO optimisation on LLMs.
How to become visible on LLM search engines?
Discover our tips to help you stand out and become visible on next-generation search engines.
1 – Understanding artificial intelligence models
Before embarking on generative AI optimisation, it is essential to fully understand the technologies behind LLMs. This will enable you to identify the future potential of SEO.
These artificial intelligence assistants go far beyond simple text matching. In other words, they do not just extract information from existing documents. Instead, they generate comprehensive, accurate, relevant, nuanced and contextually rich responses.
This is possible thanks to their linguistic comprehension and reasoning abilities (natural language processing – NLP).
Please note, however, that LLMs do not ‘understand’ internet users’ queries in the human sense of the term. They process data statistically.
2 – Deliver quality content via SEO
In essence, the main principles of SEO remain unchanged. It is always necessary to maintain the technical aspects of your website, boost its popularity with a netlinking strategy, and produce quality content.
But here, the quality requirements are even higher than before. SEO on LLMs does not seek information from sites that all say the same thing, with different turns of phrase. Instead, generative AI wants unique and accurate content, with concrete examples, figures, infographics, case studies, explicit sources, etc.
Ultimately, the more general your content is, the less likely it is to meet the requirements of generative AI optimisation.
3 – Define an SEO brand strategy
Concerned about the relevance of their sources, large language models will not promote unknown websites. They favour sites that already have a certain authority and popularity. This obviously involves a netlinking strategy, but not only that. Nowadays, you need to define a real brand identity: why are you unique?
Ultimately, generative AI optimisation goes even further than traditional SEO.
Please note that, at present, there is no proven and approved method for optimising generative AI. In fact, each model produces different results in response to the same query. It is therefore not a 100% exact science.
That said, these key principles maximise your chances of appearing on new search engines.
With Christmas shopping season approaching, SEO optimisation for LLMs is becoming essential. To capture consumers’ attention on platforms such as SearchGPT, brands must adjust their SEO strategies by incorporating optimisations tailored to generative AI. By focusing on content quality, relevant co-occurrences and visibility on reliable sources, businesses will be able to improve their positioning during this crucial period.
Christmas shopping on SearchGPT: SEO optimisations to plan for
For many people, Christmas shopping is not always a pleasant experience. So when an AI-based tool offers the possibility of providing a list of ideas tailored to a relatively specific request, including the set budget and key information about the recipient, it would be a shame not to take advantage of it. Although this practice has not yet been adopted by all suppliers, who still overwhelmingly favour Google’s search engine, it remains an increasingly worrying trend for brands, who see a growing interest in appearing among the first options offered by platforms.
For advertisers, it is therefore important to monitor their own mentions on AI-based search platforms and implement an effective SEO strategy to strengthen their online presence. This is a much more complex task than it is for search engines. On platforms such as ChatGPT, search is conversational, which makes results more contextual and personalised, and therefore more difficult to categorise.
Profound: an SEO tool to master for your holiday strategy
SEO tools have recently emerged to enable brands to obtain information about how they are mentioned in conversations. Profound, in particular, is one of the leaders in this market. This tool generates multiple conversations using variations to run them several times, in order to identify the brands most recommended by different platforms. Through this technology, brands can learn more about their own visibility in the responses provided by platforms and adapt their SEO strategy accordingly, targeting relevant keywords.
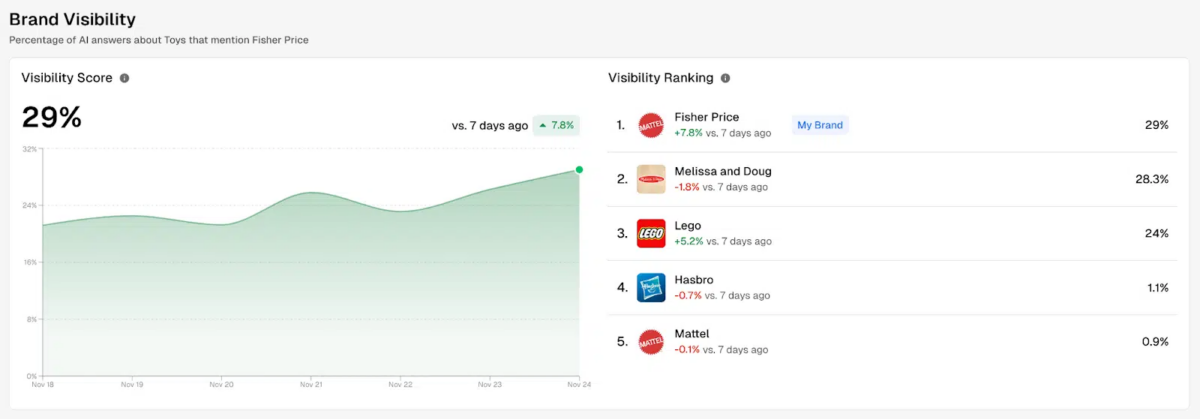
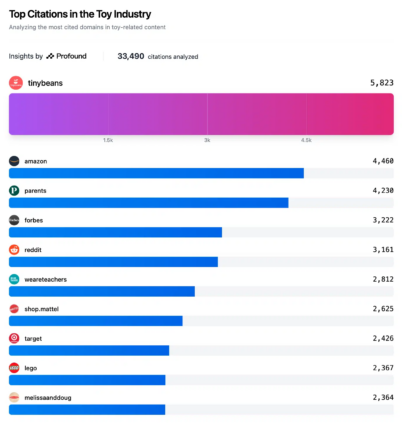
Based on a study conducted on toy retailers, the Search Engine Land website revealed some relevant information provided by Profound. The analysis tool can, in particular, provide a ranking of brand visibility on a given topic, based on conversations generated on AI-powered search platforms. The percentage shown therefore corresponds to the rate of AI responses that mention the brand in question:
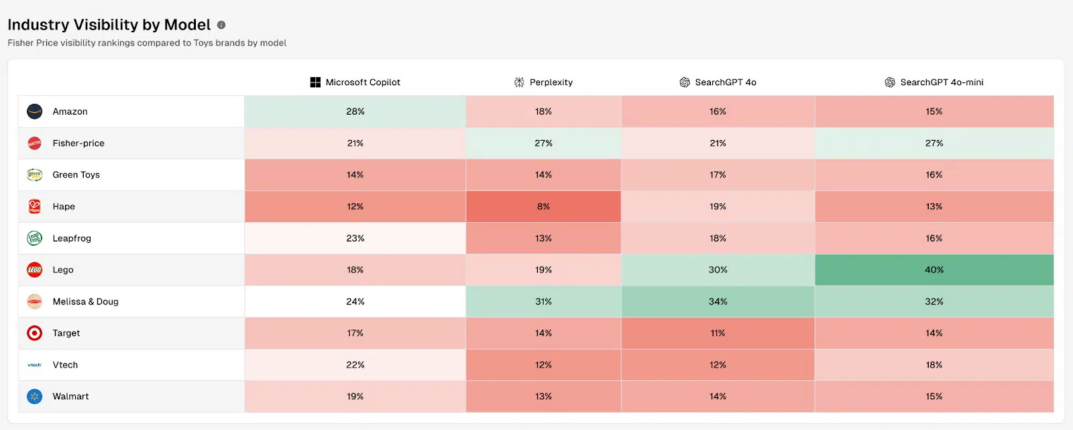
Please note that the visibility of each brand may differ depending on the platform, as the models used are not the same:
It is also possible to determine the position of each competing brand for each of the different themes provided to Profound:
Digital relationships: the secret to an SEO strategy that works on SearchGPT
But then, how did the brands mentioned above become benchmarks in their field? It’s all about SEO, so it’s worth taking a look at the sources used by AI to provide its answers.
For example, on the subject of toys, it was mainly the content on the TinyBeans website, aimed at parents, that had the greatest influence on the results. In other words, this site is considered the leading authority on toy-related content, according to various AI-based search models.
Among the top four results, there are no fewer than three content publishers, namely TinyBeans, Forbes and Parents. Conversely, content provided by the biggest brands in this market, such as Lego and Melissa & Doug, only appear at the bottom of the top 10.
While the analysis carried out on the Profound tool is not sufficient to draw a definitive conclusion about how referencing works, a clear trend seems to be emerging. Unlike search engines such as Google, which favour the quality of content provided by the brand in order to highlight it on results pages, it is third-party content that seems to take precedence on SearchGPT platforms.
Therefore, for a brand to perform well in the results delivered by these platforms, it must first and foremost be promoted within recognised sources. In addition to the SEO recommendations already mentioned, brands would be well advised to implement digital public relations strategies and work in collaboration with quality content publishers in order to gain a competitive edge over their rivals.
If you would like to increase your visibility on generative AI engines, please do not hesitate to contact our SEO agency to optimise your website.
The integration of artificial intelligence into Google Search Console marks a major breakthrough in website technical health management. This deployment automates settings that were previously manual, transforming this diagnostic tool into a powerful proactive performance lever for advertisers and SEO managers. 1. The end of manual contro...
The rollout of the February 2026 Discover Core Update marks a clear break with Google’s previous approach to managing its news feed. By prioritising local content and severely penalising clickbait practices, Mountain View is imposing a new semantic rigour. For advertisers, the challenge goes beyond simple audience reach: it is about...
Google is adding a major new feature to Search Console: a filter that automatically distinguishes branded queries from generic queries. The change may seem minor, but it transforms the way SEO is analysed. Brands can finally separate what relates to brand awareness from what relates to organic acquisition. In a context where visibility is...
Google’s results page has changed significantly since the early 2000s. Today, the search engine no longer just presents us with a list of links. It answers our questions directly using generative artificial intelligence. So yes, this new feature does mean a drop in click-through rates and traffic. But all is not lost. It is still [&...
 Leslie
Leslie